Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 15 No. 2. October 2011. (p. 23 - 27) [ISSN 1881-5537]
Confidence intervals, limits, and levels? |
 James Dean Brown University of Hawai'i at Mānoa |
[ p. 25 ]
One simple way to look at the mean of a set of scores is to think about it as a sample-based estimate of the mean of the population from which the sample was drawn. Since that estimate is never perfect, it is reasonable to want to know how much error there may be in that estimate of the population mean. The magnitude of this error can be calculated using the seM as follows:

[ p. 24 ]
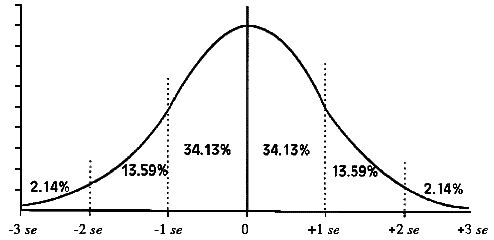
[ p. 25 ]
[ p. 26 ]
|
Where to Submit Questions: Please submit questions for this column to the following e-mail or snail-mail addresses: browrlj@hawai.edu JD Brown Department of ESL, UHM 1890 East-West Road Honolulu, HI 96822 USA |
[ p. 27 ]