Shiken:JALT Testing & Evaluation SIG Newsletter
Vol. 9 No. 1. Spring 2005. (p. 12 - 16) [ISSN 1881-5537]
Generalizability and Decision Studies |
 James Dean Brown University of Hawai'i at Manoa |
[ p. 12 ]
Roughly, in this study, the variance components estimates for individuals can be interpreted as an estimate of how much the individuals in the study varied in terms of the three measures; that is, roughly this shows simple differences between individuals. The situation variance component estimates how much prompts affect the scores. Roughly, this shows how much situations affect scores. The interaction variance components estimates [sic] the extent to which the relative ranking of individuals changes according to prompts. Basically, this shows the extent to which the scores depended on differing reactions to the 12 complaint-initiation prompts. (p. 19).
[ p. 13 ]
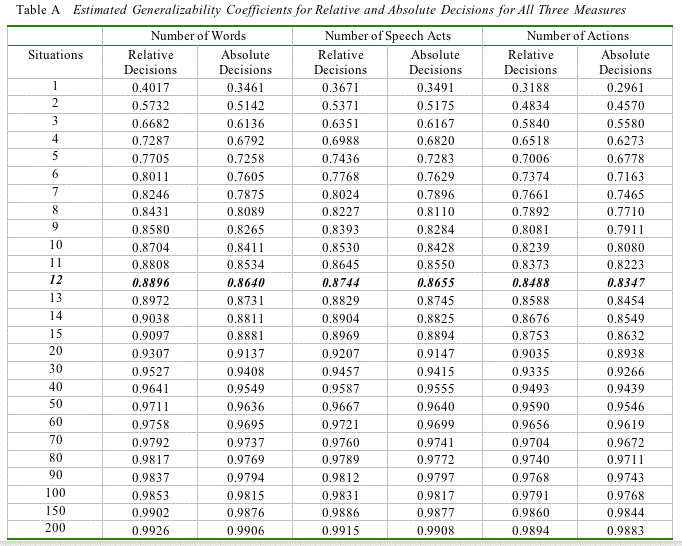
[ p. 14 ]
[ p. 15 ]
|
Bachman, L. F., Lynch, B. K., & Mason, M. (1995). Investigating variability in tasks and rater judgments in a performance test of foreign language speaking. Language Testing, 12 (2), 239-257.
Bolus, R. E., Hinofotis, F. B., & Bailey, K. M. (1982). An introduction to generalizability theory in second language research. Language Learning, 32, 245-258. Brennan, R. L. (1983). Elements of generalizability theory. Iowa City, IA: American College Testing Program. Brennan, R. L. (2001). Generalizability theory. New York: Springer-Verlag. Brown, J. D. (1984). A norm-referenced engineering reading test. In A. K. Pugh, & J. M. Ulijn (Eds.) Reading for professional purposes: studies and practices in native and foreign languages (pp. 213-222). London: Heinemann Educational Books. Brown, J. D. (1988). 1987 Manoa Writing Placement Examination. Manoa Writing Board Technical Report #1. Honolulu, HI: Manoa Writing Program, University of Hawaii at Manoa. Brown, J. D. (1989). 1988 Manoa Writing Placement Examination. Manoa Writing Board Technical Report #2. Honolulu, HI: Manoa Writing Program, University of Hawaii at Manoa. Brown, J. D. (1990a). 1989 Manoa Writing Placement Examination. Manoa Writing Board Technical Report #5. Honolulu, HI: Manoa Writing Program, University of Hawaii at Manoa. Brown, J. D. (1990b). Short-cut estimates of criterion-referenced test consistency. Language Testing, 7 (1), 77-97. Brown, J. D. (1991). 1990 Manoa Writing Placement Examination. Manoa Writing Board Technical Report #14. Honolulu, HI: Manoa Writing Program, University of Hawaii at Manoa. Brown, J. D. (1993). A comprehensive criterion-referenced language testing project. In D. Douglas and C. Chapelle (Eds.) A New Decade of Language Testing Research (pp. 163-184). Washington, DC: TESOL. Brown, J. D. (1999). Relative importance of persons, items, subtests and languages to TOEFL test variance. Language Testing, 16 (2), 216-237. Brown, J. D., & Bailey, K. M. (1984). A categorical instrument for scoring second language writing skills. Language Learning, 34, 21-42. Brown, J. D., & Hudson, T. (2002). Criterion-referenced language testing. Cambridge: Cambridge University Press. Brown, J. D., & Ross, J. A. (1996). Decision dependability of item types, sections, tests, and the overall TOEFL test battery. In M. Milanovic & N. Saville (Eds.), Performance Testing , Cognition and Assessment (pp. 231-265). Cambridge: Cambridge University. Cronbach, L. J., Rajaratnam, N., & Gleser, G. C. (1963). Theory of generalizability: A liberalization of reliability theory. British Journal of Statistical Psychology, 16, 137-163. Cronbach, L.J., Gleser, G.C., Nanda, H., & Rajaratnam, N. (1972). The dependability of behavioral measurements: Theory of generalizability of scores and profiles. New York: Wiley. Kunnan, A. J. (1992). An investigation of a criterion-referenced test using G-theory, and factor and cluster analysis. Language Testing, 9 (1), 30-49. Molloy, H., and Shimura, M. (2005). An examination of situational sensitivity in medium-scale interlanguage pragmatics research. In T Newfields, Y. Ishida, M. Chapman, & M. Fujioka (Eds.) Proceedings of the May. 22-23, 2004 JALT Pan-SIG Conference Tokyo: JALT Pan SIG Committee.(p. 16 -32). Available online at http://jalt.org/pansig/2004/HTML/ShimMoll.htm. [accessed 8 Feb. 2005]. Shavelson, R. J., & Webb, N. M. (1991). Generalizability theory: A primer. Newbury Park, CA: Sage. Stansfield, C. W., & Kenyon, D. M. (1992). Research of the comparability of the oral proficiency interview and the simulated oral proficiency interview. System, 20, 347-364. |
Where to Submit Questions:Please submit questions for this column to the following e-mail or snail-mail addresses:brownj@hawaii.edu JD Brown, Department of Second Language Studies University of Hawai'i at Manoa 1890 East-West Road, Honolulu, HI 96822 USA |
[ p. 16 ]