Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 4 No. 3 Jan 2001 (p. 7 - 11) [ISSN 1881-5537]
Can we use the Spearman-Brown prophecy formula to defend low reliability? |
 James Dean Brown University of Hawai'i at Manoa |
[ p. 7 ]
|
Table 1. Subscale and Cloze Reliabilities for a Portugese Learning Questionnaire. (Adapted from Brown, Cunha, and Frota, 2001) 
|
[ p. 8 ]
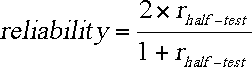
[ p. 9 ]
However, there is another version of the formula, which can be applied to situations other than a simple doubling of the number of items:[ p. 10 ]
References
|
Brown, J. D. (1996). Testing in language programs. Upper Saddle River, NJ: Prentice Hall Regents.
Brown, J. D. (trans. by M. Wada). (1999). Gengo tesuto no kisochishiki [Basic knowledge of language testing]. Tokyo: Taishukan Shoten. Brown, J. D. (1999). Relative importance of persons, items, subtests and languages to TOEFL test variance. Language Testing, 16 (2), 216-237. Brown, J. D., Cunha, M. I. A., & Frota, S. de F. N. (2001). The development and validation of a Portuguese version of the Motivated Strategies for Learning Questionnaire. In Z. Dörnyei & R. Schmidt (Eds.), Motivation and second language acquisition. Honolulu, HI: Second Language Teaching & Curriculum Center, University of Hawaii Press. Hirai, A. (1999). The relationship between listening and reading rates of Japanese EFL learners. Modern Language Journal, 83, 367-384. |
[ p. 11 ]