Shiken:JALT Testing & Evaluation SIG Newsletter
Vol. 3 No. 1 Apr. 1999. (p. 20 - 25) [ISSN 1881-5537]
Standard error vs.
|
 James Dean Brown University of Hawai'i at Manoa |
![]() ANSWER:
The most direct answer to your question is "no." Most likely, you are referring to the STEYX function in the ubiquitous ExcelTM spreadsheet. The statistic calculated by the STEYX function is commonly referred to as the standard error of estimate and that is not the standard error of measurement.
As your question suggests, the standard error of estimate is often confused with the standard error of measurement that is reported by some test analysis software, or even with the standard error of the mean that is reported by more sophisticated statistical packages like SPSS, SAS, or SYSTAT. Let me try to unscramble all of this step by step by first reviewing what the standard deviation is. Then I will be able to explain the definitions and differences among the standard error of the mean, the standard error of estimate, and the standard error of measurement.
ANSWER:
The most direct answer to your question is "no." Most likely, you are referring to the STEYX function in the ubiquitous ExcelTM spreadsheet. The statistic calculated by the STEYX function is commonly referred to as the standard error of estimate and that is not the standard error of measurement.
As your question suggests, the standard error of estimate is often confused with the standard error of measurement that is reported by some test analysis software, or even with the standard error of the mean that is reported by more sophisticated statistical packages like SPSS, SAS, or SYSTAT. Let me try to unscramble all of this step by step by first reviewing what the standard deviation is. Then I will be able to explain the definitions and differences among the standard error of the mean, the standard error of estimate, and the standard error of measurement.
Standard Deviation
![]() As I defined it in Brown (1988, p. 69), the standard deviation "provides a sort of average of the differences of all scores from the mean." This means that it is a
measure of the dispersion of scores around the mean. The standard deviation is
related to the range (another indicator of dispersion based on the distance between
the highest and lowest score), but has the advantage over the range of not being affected as much as the range by aberrant scores that are exceptionally high or low. Generally, a low standard deviation means that a set of scores is not very widely dispersed around the mean, while a high standard deviation indicates that the scores are more widely dispersed. [For more information on calculating and interpreting standard deviations, see Brown 1988 amd 1995]
As I defined it in Brown (1988, p. 69), the standard deviation "provides a sort of average of the differences of all scores from the mean." This means that it is a
measure of the dispersion of scores around the mean. The standard deviation is
related to the range (another indicator of dispersion based on the distance between
the highest and lowest score), but has the advantage over the range of not being affected as much as the range by aberrant scores that are exceptionally high or low. Generally, a low standard deviation means that a set of scores is not very widely dispersed around the mean, while a high standard deviation indicates that the scores are more widely dispersed. [For more information on calculating and interpreting standard deviations, see Brown 1988 amd 1995]
![]() It turns out that, in a normal distribution, about 68% of the students can be expected to fall in the range of scores between minus one standard deviation below the mean and plus one standard deviation above the mean and that about 95% of the students can be expected to fall in the range of scores between minus two standard deviations below the mean and plus two standard deviations above the mean. So on a test with a mean of 51 and standard deviation of 10, you can expect about 68% of the students to score between 41 and 61, and about 95% of the students to score between 31 and 71. This use of percents with the standard deviation will become important in interpreting all three of the standard error statistics described below. Now, having reviewed the basic concept of standard deviation, it is possible to consider the concept of standard error of the mean.
It turns out that, in a normal distribution, about 68% of the students can be expected to fall in the range of scores between minus one standard deviation below the mean and plus one standard deviation above the mean and that about 95% of the students can be expected to fall in the range of scores between minus two standard deviations below the mean and plus two standard deviations above the mean. So on a test with a mean of 51 and standard deviation of 10, you can expect about 68% of the students to score between 41 and 61, and about 95% of the students to score between 31 and 71. This use of percents with the standard deviation will become important in interpreting all three of the standard error statistics described below. Now, having reviewed the basic concept of standard deviation, it is possible to consider the concept of standard error of the mean.
Standard Error of the Mean
![]() Conceptually, the standard error of the mean is related to estimating the population mean in that it provides an indication of the dispersion of the sampling errors when you are trying to estimate a population mean from a sample mean. In order to understand the previous sentence you will first need to understand three bits of jargon: sampling errors, population mean, and sample mean. I'll deal with them in reverse order.
Conceptually, the standard error of the mean is related to estimating the population mean in that it provides an indication of the dispersion of the sampling errors when you are trying to estimate a population mean from a sample mean. In order to understand the previous sentence you will first need to understand three bits of jargon: sampling errors, population mean, and sample mean. I'll deal with them in reverse order.
![]() Usually, you do not have the resources to measure the entire population of students when you give a test. Typically, for instance, you administer a test to a class or group of incoming students, but not to the entire school. Also in other experimental research situations, you might find yourself taking a random sample of the population of students in order to make your measurement, data entry, analysis, and other work easier. If the sample is truly random, researchers consider it representative of the population. Nonetheless, sample statistics like the sample mean, the reliability estimate for the sample, or any other statistics based on the sample are not likely to be exactly the same as those for the population. The ones for population are referred to as population parameters. Often people measure sample statistics thinking those statistics are the same as the population parameters. For instance, you might calculate the sample mean of a random sample of 50 students on some test and assume that it is the same as the population mean for that test.
Usually, you do not have the resources to measure the entire population of students when you give a test. Typically, for instance, you administer a test to a class or group of incoming students, but not to the entire school. Also in other experimental research situations, you might find yourself taking a random sample of the population of students in order to make your measurement, data entry, analysis, and other work easier. If the sample is truly random, researchers consider it representative of the population. Nonetheless, sample statistics like the sample mean, the reliability estimate for the sample, or any other statistics based on the sample are not likely to be exactly the same as those for the population. The ones for population are referred to as population parameters. Often people measure sample statistics thinking those statistics are the same as the population parameters. For instance, you might calculate the sample mean of a random sample of 50 students on some test and assume that it is the same as the population mean for that test.
[ p. 20 ]

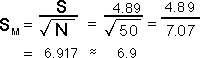
Standard Error of Measurement
![]() Conceptually, the standard error of measurement is related to test reliability in that it provides an indication of the dispersion of the measurement errors when you are trying to estimate students' true scores from their observed test scores. In order to understand the previous sentence you will first need to understand three bits of jargon: sampling errors, true scores, and test scores. I will deal with them in reverse order.
Conceptually, the standard error of measurement is related to test reliability in that it provides an indication of the dispersion of the measurement errors when you are trying to estimate students' true scores from their observed test scores. In order to understand the previous sentence you will first need to understand three bits of jargon: sampling errors, true scores, and test scores. I will deal with them in reverse order.
[ p. 21 ]

[ p. 22 ]
![]() Conceptually, the standard error of estimate is related to regression analysis in that it typically provides an estimate of the dispersion of the prediction errors when you are trying to predictY values from X values in a regression analysis. In order to understand the previous sentence, you will first need to understand three bits of jargon: prediction errors, Y values, and X values. Again, I would like to deal with those terms in reverse order. In a regression analysis, X values are any values from which you want to predict, and Y values are any values to which you want to predict. Unfortunately, those predictions are never perfect because prediction errors occur. Such errors may be due to unreliable measurement in either the Y or X variable, or due to unsystematic differences between the two sets of numbers. When you are trying to predict Y values from X values, it would be useful to know what the distribution of those prediction errors is so you can interpret your predictions wisely.
Conceptually, the standard error of estimate is related to regression analysis in that it typically provides an estimate of the dispersion of the prediction errors when you are trying to predictY values from X values in a regression analysis. In order to understand the previous sentence, you will first need to understand three bits of jargon: prediction errors, Y values, and X values. Again, I would like to deal with those terms in reverse order. In a regression analysis, X values are any values from which you want to predict, and Y values are any values to which you want to predict. Unfortunately, those predictions are never perfect because prediction errors occur. Such errors may be due to unreliable measurement in either the Y or X variable, or due to unsystematic differences between the two sets of numbers. When you are trying to predict Y values from X values, it would be useful to know what the distribution of those prediction errors is so you can interpret your predictions wisely.
![]() An example of such a situation might be a case where you use regression analysis to predict TOEFL scores from the PERFECT test at your institution. You must first conduct a study based on a large number of students who took both tests. Then using regression analysis, you build a regression equation of the form Y = a + b X. Based on your analysis, you will know the values of a (the intercept) and b (the slope), and can then plug in the X value (or PERFECT test score) for a student who has never taken the TOEFL. Solving for Y will then give you that student's predicted Y (or predicted TOEFL score). All of this is beyond the scope of this explanation, but is necessary in order to get even a basic understanding of what the standard error of estimate is. [For more on regression analysis, see Brown, 1988, or Hatch and Lazaraton, 1991].
An example of such a situation might be a case where you use regression analysis to predict TOEFL scores from the PERFECT test at your institution. You must first conduct a study based on a large number of students who took both tests. Then using regression analysis, you build a regression equation of the form Y = a + b X. Based on your analysis, you will know the values of a (the intercept) and b (the slope), and can then plug in the X value (or PERFECT test score) for a student who has never taken the TOEFL. Solving for Y will then give you that student's predicted Y (or predicted TOEFL score). All of this is beyond the scope of this explanation, but is necessary in order to get even a basic understanding of what the standard error of estimate is. [For more on regression analysis, see Brown, 1988, or Hatch and Lazaraton, 1991].
![]() We assume that any student's predicted Y score is our best estimate of that score, but we recognize that there are sampling errors around that estimate, just as there were for estimating the population mean and true scores. Those sampling errors are normally distributed and, in this case, have a standard deviation called the standard error of estimate.
We assume that any student's predicted Y score is our best estimate of that score, but we recognize that there are sampling errors around that estimate, just as there were for estimating the population mean and true scores. Those sampling errors are normally distributed and, in this case, have a standard deviation called the standard error of estimate.
![]() Fortunately, you can use the following simple formula to calculate the standard error of estimate from the standard deviation of the Y values in the original regression analysis and the correlation coefficient between the X and Y values in that analysis:
Fortunately, you can use the following simple formula to calculate the standard error of estimate from the standard deviation of the Y values in the original regression analysis and the correlation coefficient between the X and Y values in that analysis:
[ p. 23 ]
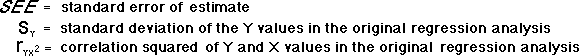
[ p. 24 ]
References
Brown, J. D. (1988). Understanding research in second language learning: A teacher's guide to statistics and research design.
London: Cambridge University Press.
Brown, J. D. (1996). Testing in language programs. Upper Saddle River, NJ: Prentice Hall.
Brown, J. D. (trans. by M. Wada). (1999). Gendo kyoiku to tesutingu. [Language teaching and testing]. Tokyo: Taishukan Shoten.
Hatch, E., & Lazaraton, A. (1991). The research manual: Design and statistics for applied linguistics. Rowley, MA: Newbury House.
[ p. 25 ]