Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 11 No. 1. Mar. 2007. (p. 31 - 35) [ISSN 1881-5537]
Sample size and power |
 James Dean Brown University of Hawai'i at Manoa |
[ p. 31 ]


[ p. 32 ]
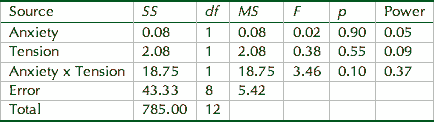
In fact, in a follow-up power analysis on the production tests, the observed power (1 - _), which is the probability of correctly rejecting the null hypothesis (Tabachnick & Fidell, 1996: 36-37), was 0.50 for the immediate posttest and 0.11 for the delayed posttest, both of which were fairly low (for more information about power analysis, see Cohen, 1988: Lipsey, 1990). This suggests that the design (i.e., n-size, distributions, and treatment magnitude) may not have been strong enough to detect significant differences.
[ p. 33 ]
The bottom line with regard to power analysis is that there is much to be gained in our understanding of the statistical results of our studies if only we will ask our statistical programs to calculate power.
[ p. 34 ]
| Where to Submit Questions: |
| Please submit questions for this column to the following address: |
|
JD Brown Department of Second Language Studies University of Hawai'i at Manoa 1890 East-West Road Honolulu, HI 96822 USA |
[ p. 35 ]