Shiken:JALT Testing & Evaluation SIG Newsletter
Vol. 7 No. 3. Dec. 2003. (p. 18 - 24) [ISSN 1881-5537]
Criterion-referenced item analysis
|
 James Dean Brown University of Hawai'i at Manoa |
[ p. 18 ]
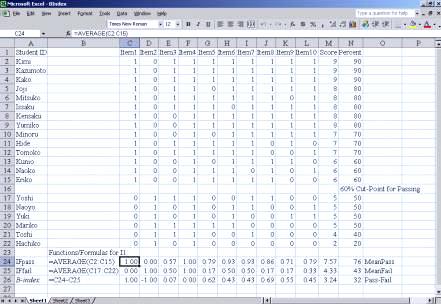
| "the difference index shows the gain, or difference in performance, on each item between the pretest and posttest." |
[ p. 19 ]

| "the B-index shows how well each item is contributing to the pass/fail decisions that are often made with CRTs." |
[ p. 20 ]
[ p. 21 ]
| "Generally, the difference index will tell you how well each item fits the objectives of your curriculum, and the B-index will tell you how well each item is contributing to the pass/fail decision that you must make at whatever cut-point you are using." |
[ p. 22 ]
[ p. 23 ]
Brown, J. D. (1995b). The elements of language curriculum: A systematic approach to program development. New York: Heinle & Heinle Publishers.|
Where to Submit Questions: Please submit questions for this column to the following e-mail or snail-mail addresses: brownj@hawaii.edu JD Brown, Department of Second Language Studies University of Hawaii at Manoa 1890 East-West Road, Honolulu, HI 96822 USA |
[ p. 24 ]