Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 11 No. 2. Aug. 2007. (p. 21 - 24) [ISSN 1881-5537]
Sample size and statistical precision |
 James Dean Brown University of Hawai'i at Manoa |
[ p. 21 ]
[ p. 22 ]
Such standard errors can be calculated for all statistical estimates of parameters and can all be interpreted the same way the degree to which the statistical estimates are likely to fluctuate, or put another way, as the degree to which the statistical estimates are precise.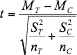
[ p. 23 ]
| Where to Submit Questions: |
| Please submit questions for this column to the following address: |
|
JD Brown Department of Second Language Studies University of Hawai'i at Manoa 1890 East-West Road Honolulu, HI 96822 USA |
[ p. 24 ]