Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 15 No. 2. October 2011. (pp. 30 - 42) [ISSN 1881-5537]
| Possible answers for the ten questions about testing/assessment which were in the October 2011 issue of this newsletter appear below. |
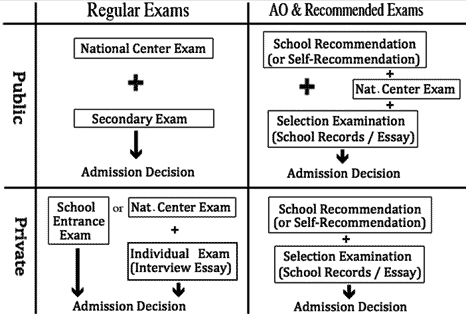
[ p. 33 ]
|
Further reading: Brown, J. D. (with T. J. Leonard). (1998). Japanese university entrance examinations: An interview with Dr. J.D. Brown. The Language Teacher, 22 (3) 303-318. Retrieved from http://www.jalt-publications.org/tlt/files/98/mar/leonard.html Daigaku Shinbunsha Shinrou Jouhou Kenkyuu Sentaa. (2011). 2011 nen-ban shinrou adbaiza kentei koushiki tekisuto. [2011 public examination advisory text] Tokyo: Author. Schoppa, L. J. (1990). Education reform in Japan: A case of immobilist politics. London: Routledge. Shoubunsha. (2011). Daigaku juken annai. [University entrance exam guide]. Tokyo: Author. Zeng, K. (1999). Dragon gate: Competitive examinations and their consequences. London & New York: Cassell. |
[ p. 34 ]
A: This is a form of cognitive bias in which respondents overrate the extent that others agree with them. In other words, it is a tendency to conflate personal opinions about an issue with those of a larger group. Fields and Schuman (1976) describe this tendency as "looking glass perceptions" in which individuals believe their views represent the views of a majority.|
Further reading: Fields, J. M. & Schuman, H. (1976). Public beliefs about the beliefs of the public. Public Opinion Quarterly, 40 (4) 427-448. DOI: 10.1086/268330 Jones, E. E., D. E. Kannouse, H. H. Kelley, R. E. Nisbett, S. Valins, and B. Weiner, (Eds). (1972). Attribution: Perceiving the causes of behavior. Morristown, NJ: General Learning Press. Wojcieszak, M. (2008). False consensus goes online: Impact of ideologically homogeneous groups on false consensus. Public Opinion Quarterly, 72 (4) 781-791. DOI: 10.1093/poq/nfn056 |
[ p. 35 ]
|
Further reading: Ray, J. J. (1990). Acquiescence and problems with forced-choice scales. Journal of Social Psychology, 130(3), 397-399. Retrieved on March 4, 2011 from http://jonjayray.tripod.com/forcho.html Macintyre, P. D., & Charos, C. (1996). Personality, attitudes, and affect as predictors of second language communication. Journal of Language and Social Psychology, 15 (1) 3-26. doi: 10.1177/0261927X960151001 Macintyre, P. D. Clément, R., Dörnyei, Z. & Noels, K. A. (1998). Conceptualizing willingness to communicate in a L2: A situational model of L2 confidence andaffiliation. Modern Language Journal, 82, 545-562. |
[ p. 36 ]
If we wish to define it narrowly as "the ability to read accurately, quickly, effortlessly, and with appropriate expression" (Rasinkski, 2003), then perhaps one of the measurement procedures outlined by Wagner and Lawton (2011) would be appropriate. If we define reading fluency more broadly to include comprehension, then some of the tests described in the Testing Reading section of the JLTA Language Testing Bibliography (2009) might be useful. Extensive field testing would be needed to ascertain whether or not any specific test would be appropriate for a given high school context.|
Further reading: Japan Language Testing Association. (2009). The JLTA language testing bibliography, Category 3: Testing reading. Retrieved from https://e-learning.ac/jlta.ac/mod/resource/view.php?id=36 Moss, S. (2009). Regression discontinuity design. Retrieved from http://www.psych-it.com.au/Psychlopedia/article.asp?id=256 Rasinski, T. V. (2003). The fluent reader. New York: Scholastic Professional Books. Trochim, W. M. K. (2006). The regression-discontinuity design. Research Methods Knowledge Base. Retrieved from http://www.socialresearchmethods.net/kb/quasird.php Wagner, R. &, Lawton, R. O. (2011). Assessment of word reading and reading fluency in English. Encyclopedia of Language and Literacy Development (pp. 1-8). London, ON: Canadian Language and Literacy Research Network. Retrieved from http://literacyencyclopedia.ca/pdfs/Assessment_of_Word_Reading_and_Reading_Fluency_in_English.pdf |
[ p. 37 ]
|
Further reading: Kobayashi, N., Ford-Niwa, J., & Yamamoto, H. (1996). Nihongo nouryoku no atarashii sokutei-hoo: SPOT. [A new way of measuring integrative ability of Japanese: SPOT]. Japanese Language Education Around the Globe, 4, 201-218. Retrieved from http://www.jpf.go.jp/e/japanese/survey/globe/06/report.html#13 |
|
Further reading: Brown, J. D. (1988). Understanding research in second language learning: A teacher's guide to statistics and research design. Cambridge University Press. Spatz, C. (2011). Basic statistics: Tales of distributions (10th edition). Belmont, CA: Wadsworth Cengage. StatSoft. (2011). Principal components and factor analysis. Retrieved from http://www.statsoft.com/textbook/principal-components-factor-analysis/ UNESCO. (2005). Factor analysis. Retrieved from http://www.unesco.org/webworld/idams/advguide/Chapt6_3.htm |
[ p. 38 ]
|
Further reading: Moss, S. (2008). Acquiescence bias. Retrieved from http://www.psych-it.com.au/Psychlopedia/article.asp?id=154 Murphey, T. (2001). Exploring conversational shadowing. Language Teacher Research 5 (2) 128-155. doi: 10.1177/136216880100500203 Nederhof, A. J. (1985). Methods of coping with social desirability bias: A review. European Journal of Social Psychology, 15 (3) 263-280. DOI: 10.1002/ejsp.2420150303 Viswanathan, M. (2005). Measurement error and research design. Thousand Oaks, CA: Sage. Weiksner, G. M. (2008). Measurement error as a threat to causal inference: Acquiescence bias and deliberative polling. Retrieved from http://polmeth.wustl.edu/media/Paper/Weiksner-Measurement%20Error%20as%20a%20Threat%20 to%20Causal%20Inference.pdf |
[ p. 39 ]
|
Further reading: Fong, D. (2011). The least significant difference (LSD). Retrieved from https://onlinecourses.science.psu.edu/stat502/node/37 GraphPad Software. (2011). Fisher's Least Significant Difference (LSD) test. Retrieved from http://www.graphpad.com/faq/viewfaq.cfm?faq=176 Lane, D. (2011). Differences between two means (independent groups). Retrieved from http://onlinestatbook.com/chapter10/difference_means.html |
[ p. 40 ]
ordinal variable (such as Likert scale scores) to ascertain - and possibly correct for - other hidden variables, known as covariates (such as foreign language ability). Of all the descriptions of this test that I have read, perhaps the most lucid for general readers is McDonald's (2009, 232-237).|
Further reading: Harlow, L. L. (2010). The essence of multivariate thinking: Basic themes and methods (Multivariate applications series). Mahwah, NJ: Lawrence Erlbaum. Hinton, P. R. (2004). Statistics explained: A guide for social science students (2nd Edition). New York: Routledge. Hopkins, W. G. (1997). A new view of statistics. Retrieved from http://www.sportsci.org/resource/stats/quiz.html McDonald, J. H. (2009). Handbook of biological statistics. Baltimore, MD: Sparky House Publishing. Also available at http://udel.edu/~mcdonald/statancova.html Stephens, L. (2008). Schaum's outline of statistics in psychology. New York: McGraw-Hill. Wendorf, C. A. (2004). Analysis of covariance (ANCOVA). Retrieved from http://www4.uwsp.edu/psych/cw/statmanual/ancovaoverview.html |
[ p. 41 ]
variables that should be considered when ranking universities. To ascertain how the actual ranking was made, readers must go at least two clicks away from the original web page. Since much Internet advertising is paid on a "per click" basis, perhaps that is the reason why the information is so decontextualized.|
Further reading: Doherty, J. D. (1999). Teaching information skills in the information age: The need for critical thinking. Library Philosophy and Practice, 1 (2). Retrieved from http://unllib.unl.edu/LPP/doherty.htm |
[ p. 42 ]