Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 13 No. 3. November 2009 (p. 29 - 38) [ISSN 1881-5537]
| Possible answers for the nine questions about testing/assessment which were in the November 2009 issue of this newsletter appear below. |
[ p. 29 ]
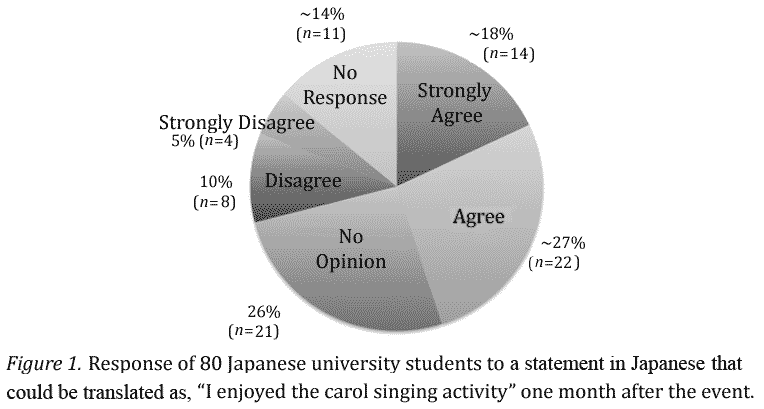
[ p. 30 ]
A: Let's first consider some issues about the essay exams, then the interviews.[ p. 31 ]
Brown, J. D. (2002) English language entrance examinations: A progress report. In A. S. Mackenzie & T. Newfields (Eds). Curriculum Innovation, Testing and Evaluation: Proceedings of the 1st Annual JALT Pan-SIG Conference. May 11-12, 2002. Kyoto, Japan: Kyoto Institute of Technology. Retrieved November 24, 2009 from http://jalt.org/pansig/2002/HTML/Brown.htm 3 Q: (1) What are the pros and cons of balancing the correct answer choice sequences in the answer sheets of fixed-response exams? What alternative ways of organizing multiple-choice key answers currently exist?
3 Q: (1) What are the pros and cons of balancing the correct answer choice sequences in the answer sheets of fixed-response exams? What alternative ways of organizing multiple-choice key answers currently exist?
[ p. 32 ]
Bar-Hillel, B., & Attali, Y. (2002). Seek whence: Answer sequences and their consequences in key-balanced multiple-choice tests. The American Statistician 56, 299-303. doi: 10.1198/000313002623.[ p. 33 ]
Gigawiz. Ltd. (2009). Correlation Methods and Statistics. Retrieved December 1, 2009 from http://www.gigawiz.com/correlations.html[ p. 35 ]
| Table 1. A Comparison of Three Widely Used Tests of Reliability. | |||
|---|---|---|---|
| KR-20 | KR-21 | Cronbach's Alpha | |
| Used for partial credit items? | No | No | Yes |
| Assumes test items are of uniform difficulty? | No | Yes | Yes |
| Single administration? | Yes | Yes | Yes |
| Assumes all test items measure same skill? | Yes | Yes | Yes |
| Recommended for speeded tests? | No | No | No |
[ p. 36 ]
4 Q: The grading scheme which appears at http://jalt.org/test/SS8c.gif is an example of __________.[ p. 37 ]
Further reading:[ p. 38 ]