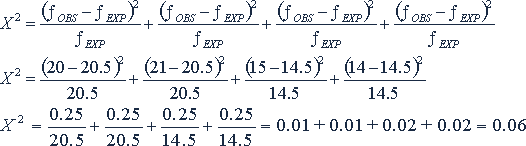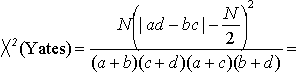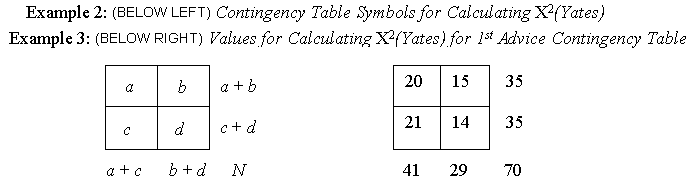Example 1: Reanalysis of Shimura's 2004 data
|
[
p. 22
]
Calculating X2 in two-way analyses
The steps for calculating the X2 value in two-way analyses are as follows:
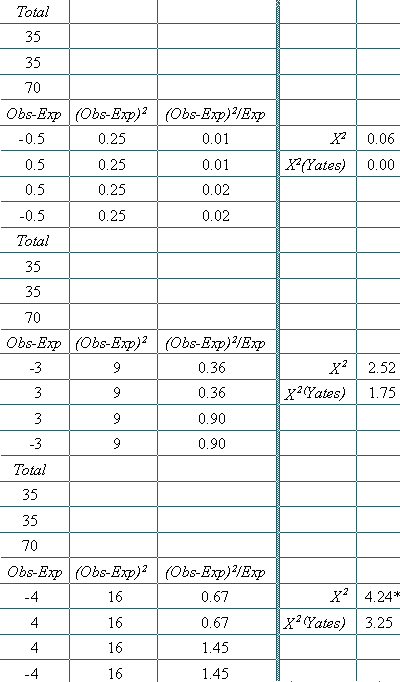
Step 1 - Line up the observed frequencies as shown in the first column just below the 1st Advice contingency table in Example 1.
Step 2 - Calculate the appropriate expected frequency for each observed frequency [multiply the row total for each cell times the column total for the same cell and divide the result by the overall total = (R x C)/T]. For example, the expected frequency for the first cell in the upper left corner of the contingency table in Example 1 (with an observed frequency of 20) would be (R x C)/T = (35 x 41)/70 = 1435/70 = 20.5 for the cell. Example 1 shows the same calculations for each of the four expected frequencies in the 1st Advice contingency table.
Step 3 - For each cell, subtract the expected frequency from the observed frequency, as shown in Example 1 with the observed frequency in the first column minus the expected frequency in the third column giving a result shown in the fourth column. For example, for the first cell, the calculation would be 20 - 20.5 = -0.5.
Step 4 - Square each of the results from Step 3 in the fourth column, and put the result in the fifth column; for the first cell, this results equals 0.25.
Step 5 - Divide each of the squared values obtained in Step 4 by the expected frequency, as shown in the sixth column, which equals 0.25/20.5 = 0.012 or about 0.01 for our example cell.
Step 6 - Repeat steps 2-5 for each cell, as shown for the 1st Advice contingency table.
Step 7 - To get the observed value of X2 for the whole contingency table, add up the Step 5 results for all four cells, which for the 1st Advice contingency table would be 0.01 + 0.01 + 0.02 + 0.02 = 0.06 (the X2 shown for the 1st Advice contingency table, at the right side of Example 1).
|