Shiken:JALT Testing & Evaluation SIG Newsletter
Vol. 6 No. 3. Sep. 2002. (p. 15 - 21) [ISSN 1881-5537]
PDF Version
Distractor efficiency analysis on a spreadsheet |
 James Dean Brown University of Hawai'i at Manoa |
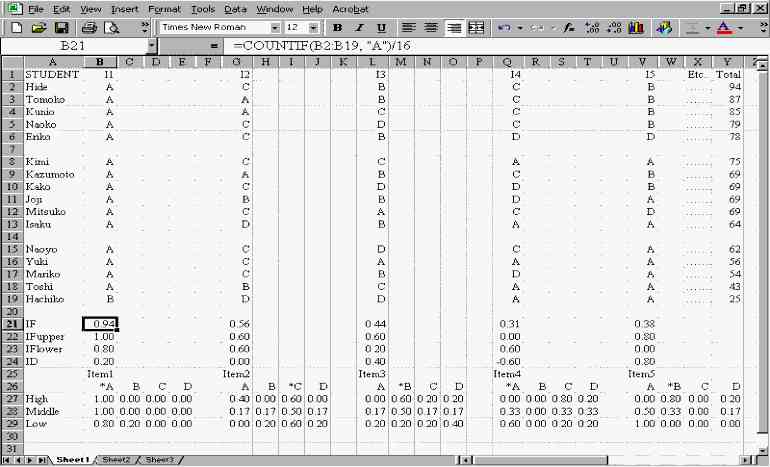
Screen 1: The Setup for Distractor Efficiency Analysis
[ p. 20 ]
Item Analysis in a Spreadsheet
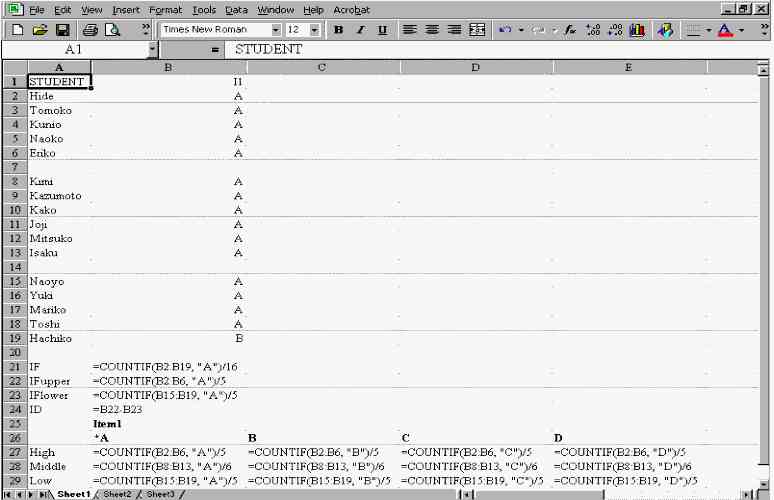
Screen 2: Formulas for Distractor Efficiency Analysis of Item One
[ p. 21 ]
[ p. 22 ]
|
Brown, J. D. (1996). Testing in language programs. Upper Saddle River, NJ: Prentice Hall.
Brown, J. D. (translated into Japanese by M. Wada). (1999). Gengo tesuto no kisochishiki [Basic knowledge of language testing]. Tokyo: Taishukan Shoten. Brown, J. D. (2000). Statistics Corner. Questions and answers about language testing statistics (How can we calculate item statistics for weighted items?). Shiken: JALT Testing & Evaluation SIG Newsletter, 3(2), 19-21. Retrieved on July 1, 2002 from the World Wide Web at http://jalt.org/test/bro_6.htm. |
| Where to Submit Questions: |
| Please submit questions for this column to the following address: |
|
JD Brown Department of Second Language Studies University of Hawai'i at Manoa 1890 East-West Road Honolulu, HI 96822 USA |
[ p. 23 ]