JALT Testing & Evaluation SIG Newsletter
Vol. 14 No. 2. October 2010. (p. 11 - 18) [ISSN 1881-5537]

 PDF Version
PDF Version
Jeffrey Stewart and Aaron Gibson (Kyushu Sangyo University) |
| Abstract |
|
The authors illustrate how classroom pre-tests can be used to gather information for an item bank from which to construct summative post-tests of appropriate levels and measurement properties, and detail methods for equating pre and post-test forms under item response theory in such a manner that resulting ability estimates between conditions are comparable. Keywords: Item Response Theory, test equating, classroom assessment |

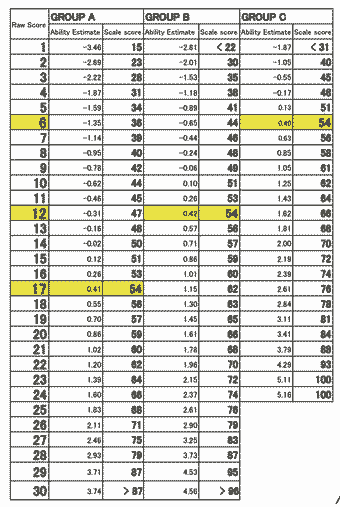
 to such a degree that students at a given institution are often strikingly homogenous in ability. For this reason, the authors find that a post-test centered to the mean of the groups' pre-test ability is often adequate for fair assessment of individuals' growth from the pre-test estimates of ability. However, if groups of students vary greatly in ability, a post-test centered in prior mean ability may not be appropriate for all test takers, as the maximum test information may then be located well above or below the ability level of groups of students at the tails of the distribution. For this reason, it may be appropriate to artificially divide students into level groups when grading, using the pre-test scores. Schools that conduct a placement test for classroom streaming are unlikely to need this procedure.
to such a degree that students at a given institution are often strikingly homogenous in ability. For this reason, the authors find that a post-test centered to the mean of the groups' pre-test ability is often adequate for fair assessment of individuals' growth from the pre-test estimates of ability. However, if groups of students vary greatly in ability, a post-test centered in prior mean ability may not be appropriate for all test takers, as the maximum test information may then be located well above or below the ability level of groups of students at the tails of the distribution. For this reason, it may be appropriate to artificially divide students into level groups when grading, using the pre-test scores. Schools that conduct a placement test for classroom streaming are unlikely to need this procedure.