Shiken: JALT Testing & Evaluation SIG Newsletter
Vol. 12 No. 2 Apr. 2008 (p. 26 - 31) [ISSN 1881-5537]

 PDF Version
PDF Version
|
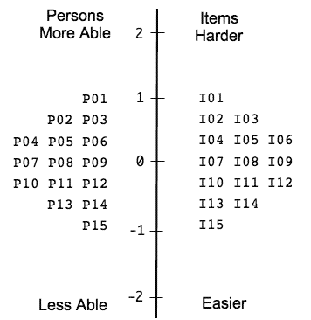
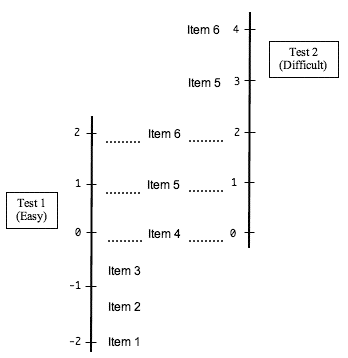
Rasch Measurement in Language Education Part 2: Measurement Scales and Invariance James Sick, Ed.D. (J. F. Oberlin University, Tokyo) |