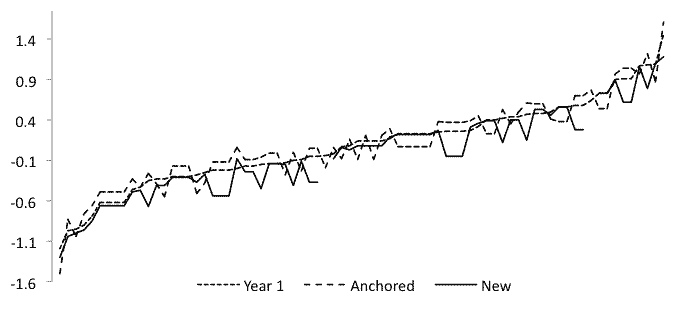
The results of analyzing a set of tests used for measuring classroom progress in EFL reading are reported.
Some 353 students in Japanese university English classes took one of four tests in 2008 and 2009. Student ability scores were derived using three analytic situations: all students together,
271 students from 2008 only, and 82 students from 2009 scored with items anchored at levels set the previous year. Student scores differed noticeably in the three analytic
situations, showing that item linking is necessary for intergroup comparisons. In other words, if you're not using the same tests, you cannot compare students.
Keywords: language testing, Rasch measurement, test-score correlation, classroom testing, criterion-referenced testing, test-item linking
|


 PDF Version
PDF Version