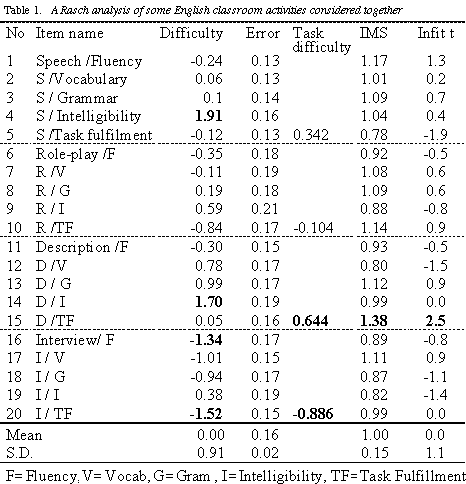
Research question 3 investigated the difficulty of tasks (items) on each
task. As indicated in the fifth column in Table 1, the description task
is the most difficult and the interview task the easiest. The difference
between the most difficult and the easiest tasks is approximately 1.5
logits.
[
p. 6
]
Research question 4 examined the quality of items, and the extent to
which data patterns derived from the Rasch model differ from those of
the actual data. Unexpected items that the Rasch model identifies are
called either "misfit" or "overfit" items. The acceptable range of IMS
here is from 0.70 to 1.30. As can be seen, only Item 15 is identified as
a "misfit," indicating a larger than the acceptable range of IMS in the
sixth and seventh columns. This shows that the actual data patterns from
item 15 (Description: task fulfillment) varied unacceptably in comparison
with data patterns estimated by Rasch measurement. Thus the items on
four tasks appeared to produce relatively similar response patterns,
suggesting that the items across tasks assessed the similar construct.
Person fit indexes

The last question focuses on students' scores across the four tasks.
This is particularly important, since this question leads to issues of
accountability for students. As can be seen in Table 2, 5.4% of the
students were identified as misfit students. This indicates that the
percentage of misfit students exceeds the limit of the acceptable
percentages of misfit students. It is important to investigate why this happened.
[
p. 7
]
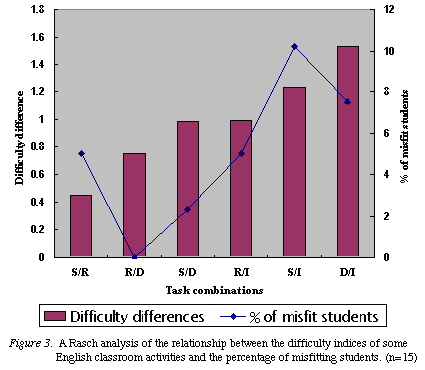
Figure 3 shows which combination of tasks tended to produce misfitting
students. Two combinations that seemed to produce misfitting students were:
(1) speeches and interviews (S/I) and descriptions and interviews (D/I).
Other task combinations
produced fewer misfit students than the above two combinations. One
possible explanation for this is that differences of task difficulty in
combinations might have an impact on increasing misfit students.
If we look at Figure 4, we can see how speaking skills are assessed in
considerably different ways by high school teachers in Japan. Over 22%
of the nearly two hundred teachers responding to this survey indicated that
they relied of a combination of speech analysis (SP), class observation
(OB) and pencil-and-paper tests (PE) to assess speaking skills. However,
it is worth noting that over 17% of the teachers relied solely on classroom
observations to assess speaking skills.
Discussion
|
"the inclusion of the speaking tests has the potential to assist in bridging the gap between skills taught in classes and skills tested in entrance examinations, and between goals of the guidelines and assessment policy. " |

|
Results of the questionnaire survey revealed that teachers' assessment
methods varied, suggesting that it would be difficult to compare
students' speaking ability across schools. The introduction of speaking
tests would have a positive impact on approximately 80% of public
English junior high school teachers in Tokyo, and most teachers
maintained that they would change to a more communicative style of
teaching. Thus, it can be argued that the inclusion of the speaking
tests has the potential to assist in bridging the gap between
skills taught in classes and skills tested in entrance examinations, and
between goals of the guidelines and assessment policy.
[
p. 8
]
Results from test trials undertaken by junior high school students
showed that all items except one fit Rasch measurement, indicating
that items on each task were effective in assessing the target
construct. However, results also showed that the four tasks frequently
used by English teachers were different in terms of difficulty. This
means that students who undertake a variety of difficulties of tasks
might not be assessed appropriately. Given that variables, including
rater behavior and interlocutors, are inherent in performance tests,
difficulty of tasks needs to be relatively equal in order to reduce
variables. The concept of task banks, presented by Brindley (2001), and
item banks by Ikeda (2000) could have important implications for the
introduction of formal speaking tests in entrance examinations:
Conclusion
Implications for this study are that speaking tasks used in a classroom
need to be trialed, and also investigated with Rasch measurement, given
that school-based assessment represents half of the selection
procedures for students who wish to enter senior high schools. In junior high school
contexts, a role play task bank, such as shopping situation, inviting
friends to a party, or giving directions to a stranger could be
developed. In order to not only administer speaking tests in a high
stakes context, but also to enable teacher implemented assessment to be
comparable across schools, it would be necessary to investigate tasks
with Rasch techniques, based on empirical data, and to build up a task
bank with a relatively consistent quality of tasks.
References
Akiyama, T. (2001). The application of G-theory and IRT in the analysis of data from speaking tests administered in a classroom context.
Melbourne Papers in Language Testing. 10 (1), 1 - 22.
Alderson, J. C., and Wall, D. (1993). Does washback exist? Applied Linguistics, 14, 115 - 129.
Bachman, L. F. (1990). Fundamental consideration language testing. Oxford University Press
Bachman, L. F., and Palmer, A. S. (1996). Language testing in practice. Oxford University Press.
Brindley, G. (2001). Outcome-based assessment in practice: some examples and emerging insights. Language Testing. 18, (4) 393-407.
[
p. 9
]
Cheng, L. (1997). How does washback influence teaching? Implications for Hong Kong. Language and Education, 11 (1), 38-54.
Ikeda, H. (1999). What we need for research on language testing in Japan – A
psychometrician's view. 21st Century Language Testing Research Colloquium. Plenary speech made at LTRC 99 Tsukuba in Japan.
Japanese Ministry of Education, Culture, Sports, Science and Technology. (1998). Chugakuko Shidosho: Gaikokugo-Hen.
[Guidelines for Junior High Schools: Foreign Language Study Revisions]. Tokyo: Kairyudo.
McNamara, T. F. (1996). Measuring second language performance. London and New York: Addison-Wesley Longman.
Messick, S. (1996). Validity and washback in language testing. Language Testing, 13 (3), 239 - 256.
Shohamy, E., Donitsa-Schmidt, S., & Ferman, I. (1996). Test impact revisited: washback effect over time.
Language Testing, 13 (3), 298-317.